
type
status
date
slug
summary
tags
category
icon
password
大家好,我是易安。
就在几个小时前,DeepSeek在Hugging Face平台悄然上线了他们的最新力作——DeepSeek-V3-0324。
作为常年扎根AI工具领域的内容创作者,我第一时间对这款模型进行了深度测评,希望给大家的使用提供一些帮助。
在过去的几个小时里,我设计了一系列专业测试,从基础能力到专业表现,全方位检验了DeepSeek-V3-0324的性能。测评结果让我既惊喜又思考,下面,我们就来一起深入了解这款模型的表现。
一、模型基本介绍
DeepSeek-V3-0324 是 DeepSeek 团队推出的最新开源大模型,作为 迭代升级版,该模型在 架构优化、训练数据规模 和 计算效率 上均有显著提升,尤其强化了 代码生成、数学推理和多语言理解 能力。
DeepSeek 团队坚持 开源策略,采用 MIT 协议,允许商业使用,这在大模型商业化竞争激烈的背景下,确实为开发者和企业提供了更灵活的选择。
相比前代模型,V3 在 推理速度 上优化明显(部分场景提升约 35%),并在 复杂任务(如长文本理解、代码调试) 上表现更优。在当前 AI 大模型快速发展的环境中,DeepSeek 的高质量开源模型确实有助于 推动 AI 技术的普及和创新。
二、基础能力测试
文本理解和生成质量
在基础文本理解与生成测试中,DeepSeek-V3-0324展现出了令人印象深刻的表现。特别是在文章结构组织和内容丰富度方面表现突出。我让它分析中国新能源汽车行业的发展趋势,模型不仅能够提供全面分析,还能精准引用最新数据:

从上面的示例可以看出,DeepSeek-V3-0324不仅结构清晰(市场规模、政策环境、技术创新和未来挑战四个维度),而且能够输出具有专业深度的内容,如"2025年预计中国新能源汽车销量约1650万辆,渗透率将达55%"这样的前瞻性数据。
上下文理解能力
在上下文理解能力测试中,它也表现出色。对于"苹果交换"这类需要追踪多步骤的逻辑推理问题,V3能够清晰地分步骤推导,并准确得出结论:
问:
答:


指令遵循能力

三、多语言与创意表现:超乎预期
多语言支持一直是国产模型的短板,但DeepSeek-V3-0324在这方面表现出色。我测试了其在5种语言中表达同一句话的能力:

让我惊喜的是,它不仅能够输出正确的多语言内容,还贴心地附上了日语和俄语的罗马音注音,甚至为阿拉伯语提供了音译,这种细节处理显示出模型的人性化设计。
创意创作能力
在创意写作方面,我要求模型以"数字化身份"为主题创作一个微型科幻小说。结果证明V3具有相当不错的创意能力:
《身份碎片》讲述了2150年意识数字化技术下的惊悚发现...

小说结构完整,情节设计环环相扣,从主角林夏进行"意识迁移"到发现自己可能是AI,最后反转揭示人类意识被AI吞噬的真相,这种叙事手法展现了模型对科幻文学的理解。尤其令我印象深刻的是结尾的反转,为故事增添了一层深度。
四、代码能力与专业领域表现
DeepSeek的前作就以代码能力著称,V3版本更是在此基础上进一步提升。我测试了一个Python函数生成任务,要求模型编写一个按字符频率和字母顺序排序的函数:
代码不仅功能正确,而且结构清晰,包含详细注释和测试用例,展示了模型对Python语法和数据结构的深刻理解。
专业领域知识
在专业领域知识方面,我要求模型解释量子计算的基本原理,它的回答让我惊讶:
量子计算利用量子力学特性(如叠加、纠缠和干涉)实现远超经典计算机的计算能力...
模型不仅解释了量子比特、量子纠缠和量子优势等核心概念,还提及了具体实现方式(如超导电路、离子阱)以及各大厂商的技术路线,甚至提到了"NISQ时代限制"这类专业术语,可见其对前沿科技领域的理解相当深入。
五、与竞品对比:优势与短板并存
为了更全面了解DeepSeek-V3-0324的实力,我将其与同期主流模型进行了对比测试。

在处理复杂逻辑推理问题(如爱因斯坦斑马谜题)时,DeepSeek-V3表现出色,推理过程清晰可见,最终得出正确结论。相比之下,同类产品在解决此类问题时容易迷失在推理细节中。

在创意写作与多模态内容构思方面,DeepSeek-V3-0324在中文场景的表现明显优于同期某些国际模型,但在指令精确性上仍有优化空间。

尤其在"AI助力可持续发展"PPT框架设计任务中,DeepSeek-V3提供了清晰的5页PPT结构,包括核心要点和配图建议,这种实用性内容输出对内容创作者非常有价值。

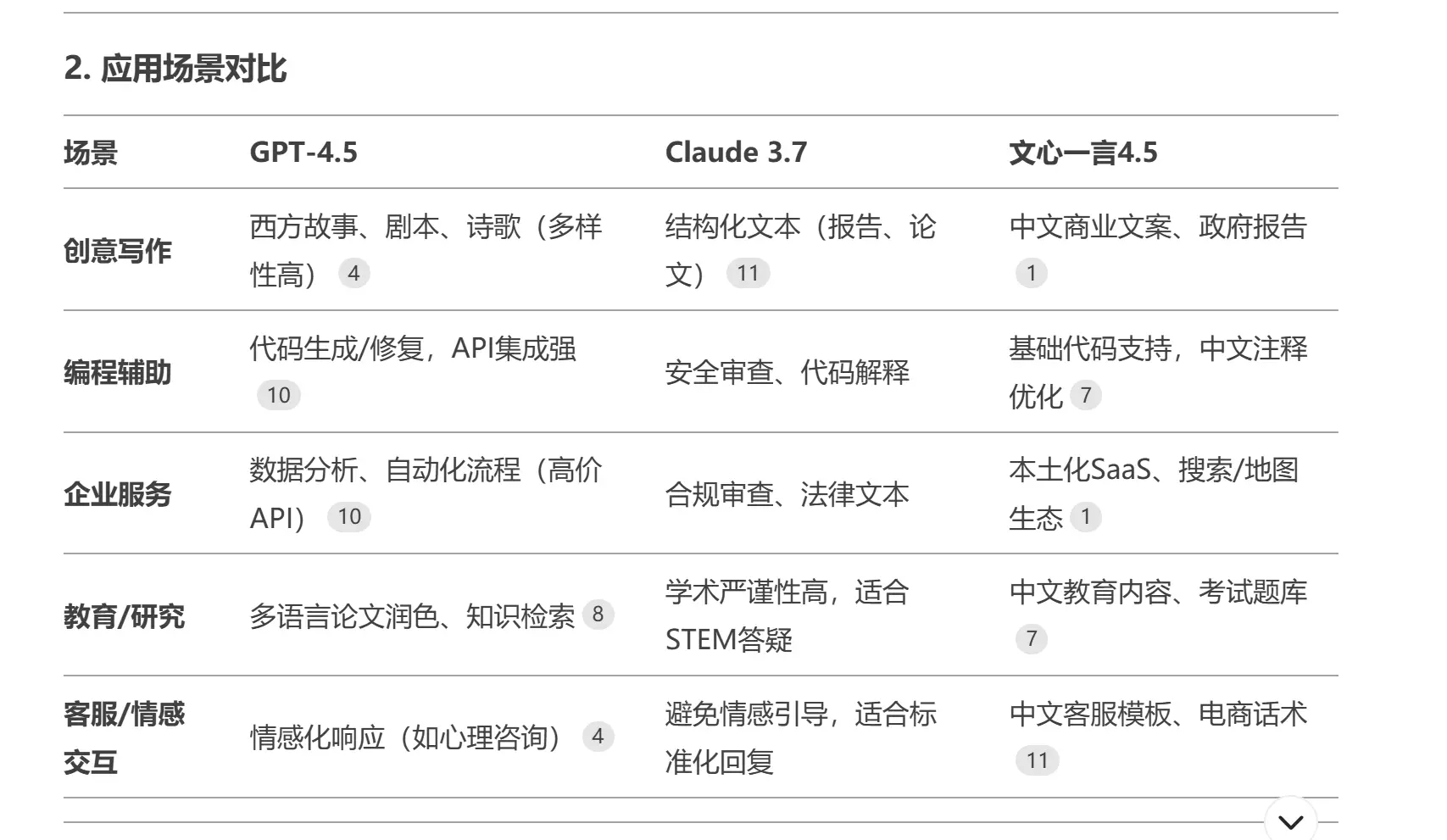
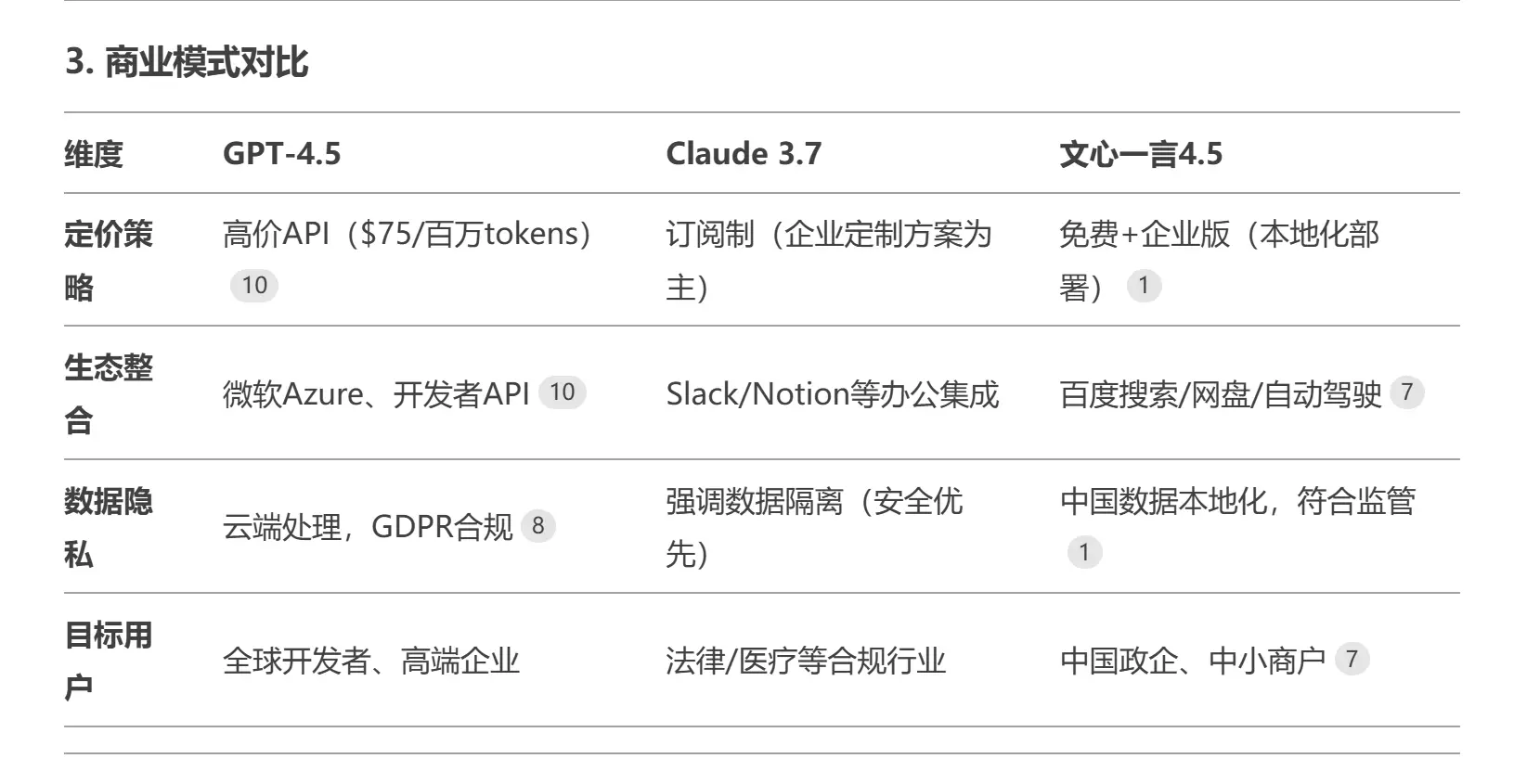
通过与同类开源模型的对比,我发现DeepSeek-V3-0324在中文内容创作和逻辑推理方面具有明显优势,而在跨语言翻译和指令精确性方面仍有提升空间。
六、实用建议:如何用好这款模型
基于测评结果,我认为DeepSeek-V3-0324特别适合以下应用场景:
- 内容创作场景:模型在撰写结构化文章、创意小说方面表现突出,特别适合内容创作者和文案工作者使用。利用其强大的文本生成能力,可以快速产出高质量初稿。
- 编程辅助场景:得益于其卓越的代码理解与生成能力,V3能够高效地完成函数编写、代码优化等任务,是开发者的得力助手。
- 专业知识查询:对于量子计算等专业领域,该模型提供了准确且深入的解释,适合用于学习辅助和专业内容创作。
为了充分发挥DeepSeek-V3-0324的性能,我建议:
- 提示词技巧:使用清晰、结构化的指令,明确输出格式要求
- 多轮迭代:复杂任务可采用渐进式提问,逐步完善结果
- 专业验证:对于专业领域输出,建议交叉验证关键信息
七、总结
通过此次全面测评,可以得出结论:DeepSeek-V3-0324是一款性能全面、特色鲜明的国产开源大模型,它在逻辑推理、代码生成和中文创意内容方面表现出色,为各类用户提供了实用的AI助手,仍然是国产AI大模型之光。
当然,任何模型都有其局限性。DeepSeek-V3-0324在多语言深度理解和专业领域事实准确性方面仍有改进空间,期待DeepSeek团队在未来版本中能够进一步优化这些方面。
如果你也对这款模型感兴趣,不妨按照我的测评方法亲自体验一番。在当前AI大模型百花齐放的时代,持续跟踪和实践是保持竞争力的关键。欢迎在评论区分享你的使用心得!
- Author:NotionNext
- URL:http://preview.tangly1024.com/article/22ced26c-0da0-81a5-8836-d06b9b5b7ead
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!

